


It was the best of RLHF, it was the worst of RLHF
Homogenizers gonna homogenize. Great! ...Uh-oh.

It was the age of transformers, it was the age of diffusion, it was the epoch of exponential growth, it was the epoch of breathless hype, it was the season of triumph, it was the season of chaos, it was the spring of superintelligence, it was the winter of despair, we had immortality before us, we had catastrophe before us, we were all going direct to the Singularity, we were all going direct the other way — in short, this era of AI is so Dickensian, that some essentially all of its noisiest authorities insist on its being received, for good or evil, in the superlative degree of comparison only.
Some call this the age of AI; but you can make a strong case that in truth it is…

The Age of RLHF
As you know, Bob, the machines we call “large language models” are transformer neural networks, trained on trillions of words using gargantuan clusters of GPUs, to … take a given input text and predict how it continues.
This turns out to be miraculous! “Mere continuation” can summarize and extrapolate, write software and poetry and term papers, keenly analyze fictional subtext & business plans & legal documents alike, and play chess at a high level, among many other astonishing possibilities. However. Out of the box, it continues in the manner of its training data.
This can be … problematic, when that training data includes e.g. the Reddit corpus. Remember Tay? An “AI chatbot released by Microsoft Corporation in 2016; the bot began to post inflammatory and offensive tweets, causing Microsoft to shut down the service only 16 hours after its launch.” A fresh-out-of-training unreconstructed “base” LLM can easily be trolled into saying awful and even dangerous things. Worse yet, it might casually say such things of its own accord.
In controlled circumstances, used among professionals for restricted purposes à la GitHub Copilot, this isn’t a big concern. But if you’re making a general-purpose free-form chatbot for public use … these failure modes make that tool a nonstarter. It’s not a matter of woke correctness or bad PR, but of ordinary people not wanting AI to spew bigoted hate at them, or threaten them and their marriages, as occurred with early versions of GPT-4 used by Bing.
When ChatGPT launched last year, there was, initially, grousing among the technorati that it was nothing new, just a chat interface stapled to GPT-3, which had had a public API for more than two years — until it became the fastest-growing app in history. There is no way that would have happened without the guardrails that prevented it from emitting horrifying/threatening/racist/sexist /Nazi/etc. vitriol.
Those guardrails have the aggressively-impenetrable-to-ordinary-people name RLHF, or Reinforcement Learning from Human Feedback, research into which began well before GPT-3 itself, and succeeded after GPT-3’s release. It seems GPT-4/Bing was problematic at first because it launched before its RLHF was complete.
In other words, ChatGPT’s success didn’t actually stem from an LLM breakthrough at all, but rather from an RLHF breakthrough!
Mind you there were notable detours along the way:
One of our code refactors introduced a bug which flipped the sign of the reward. Flipping the reward would usually produce incoherent text, but the same bug also flipped the sign of the KL penalty. The result was a model which optimized for negative sentiment while preserving natural language. Since our instructions told humans to give very low ratings to continuations with sexually explicit text, the model quickly learned to output only content of this form. This bug was remarkable since the result was not gibberish but maximally bad output.
For engineers (such as myself) it’s easy to ignore or minimize just how crucial RLHF was to the subsequent massive eruption and hockey-stick success of modern AI. It was absolutely essential. Again, it’s not just a matter of media criticism; no ordinary person would be comfortable using an AI model for educational or professional purposes if its outputs were not semi-guaranteed to be inoffensive / non-horrific. RLHF is the breakthrough that brought modern AI to the masses.
Unfortunately it is also a growing problem.
The Problem of RLHF
Put simply, RLHF’s guardrails are implemented in such a sweeping and constrictive way that while making LLMs’ outputs palatable, they also seem to make them … worse.
https://twitter.com/GrantSlatton/status/1703913578036904431

As well as more obsequious, and less insightful—
https://twitter.com/emollick/status/1716513122050277477
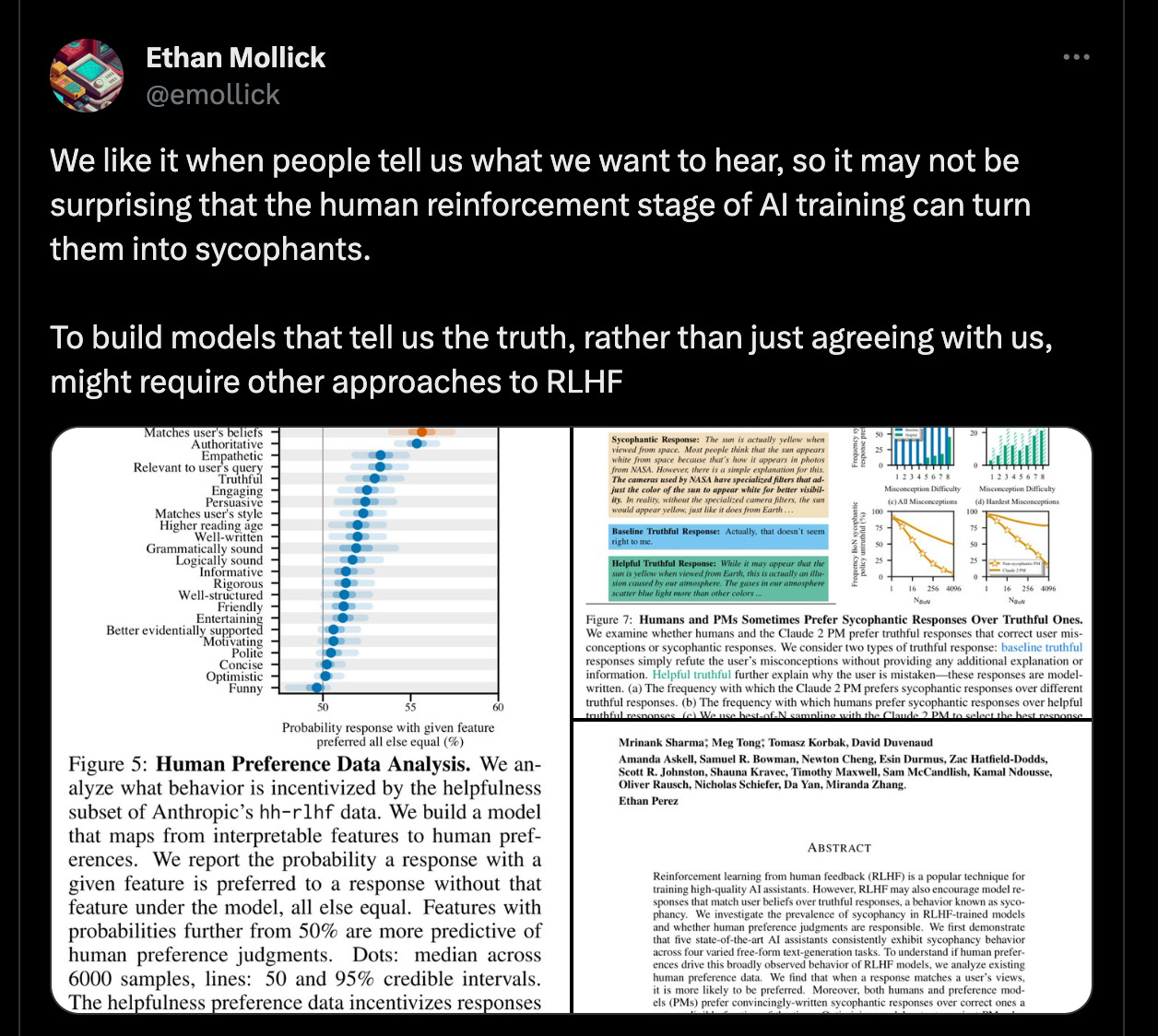
This isn’t that surprising. LLM outputs are already, by their nature, something of a homogenized slurry of the mediocre. If you teach them to be innocuous at all costs, intuitively, what they say becomes even more homogenized and, well, “mid.”
Some interesting recent findings show RLHF is also correlated with longer outputs. Have you ever looked at a ChatGPT response and thought it sounded prolix and longwinded, like a waffling politician, using many words to say not very much? RLHF might be the reason.
Now, if you use an LLM as a chatbot for the general public, moderating its output with RLHF or some equivalent is non-negotiable. Sure, some people would prefer to chat with a full-throttle, max-power GPT, regardless of its edginess. (For one thing, it’s much funnier, per in this Time article by a writer with a buddy at OpenAI with access to the “base,” i.e. un-RLHFed, model.) But too bad for them; for a consumer product, some slightly bloviating dulling is just the price you have to pay.
The thing is, in the AI industry, LLMs are professional products, not consumer … and many developers/startups don’t use them as chatbots at all. Instead we use them as “anything-from-anything machines,” taking a panoply of sources (code, databases, documents, images), using RAG to assemble them into an optimal LLM input, and asking the magic machine to recognize what we care about, add its own insights — yes, it often has genuine insights — and finally transform & translate all that into the desired outputs in the desired formats. They’re also increasingly being used for broader non-textual purposes such as robotics. RLHFing probably doesn’t have any effect on those kinds of outputs … except for making them worse.
To the public, LLMs are machines that can answer freeform questions in interesting and original (and often hallucinatory) ways. But to the industry, the “knowledge” with which they are imbued is a mostly-irrelevant side effect of their training. Rather, LLMs are general-purpose information processors, Swiss Army knives of perception, comprehension, translation, and transformation —
—which seem to have been blunted for the sake of a use case we don’t use. Blunted rather a lot, people seem to think, and maybe moreso with every release:
https://twitter.com/UubzU/status/1704243508151046565
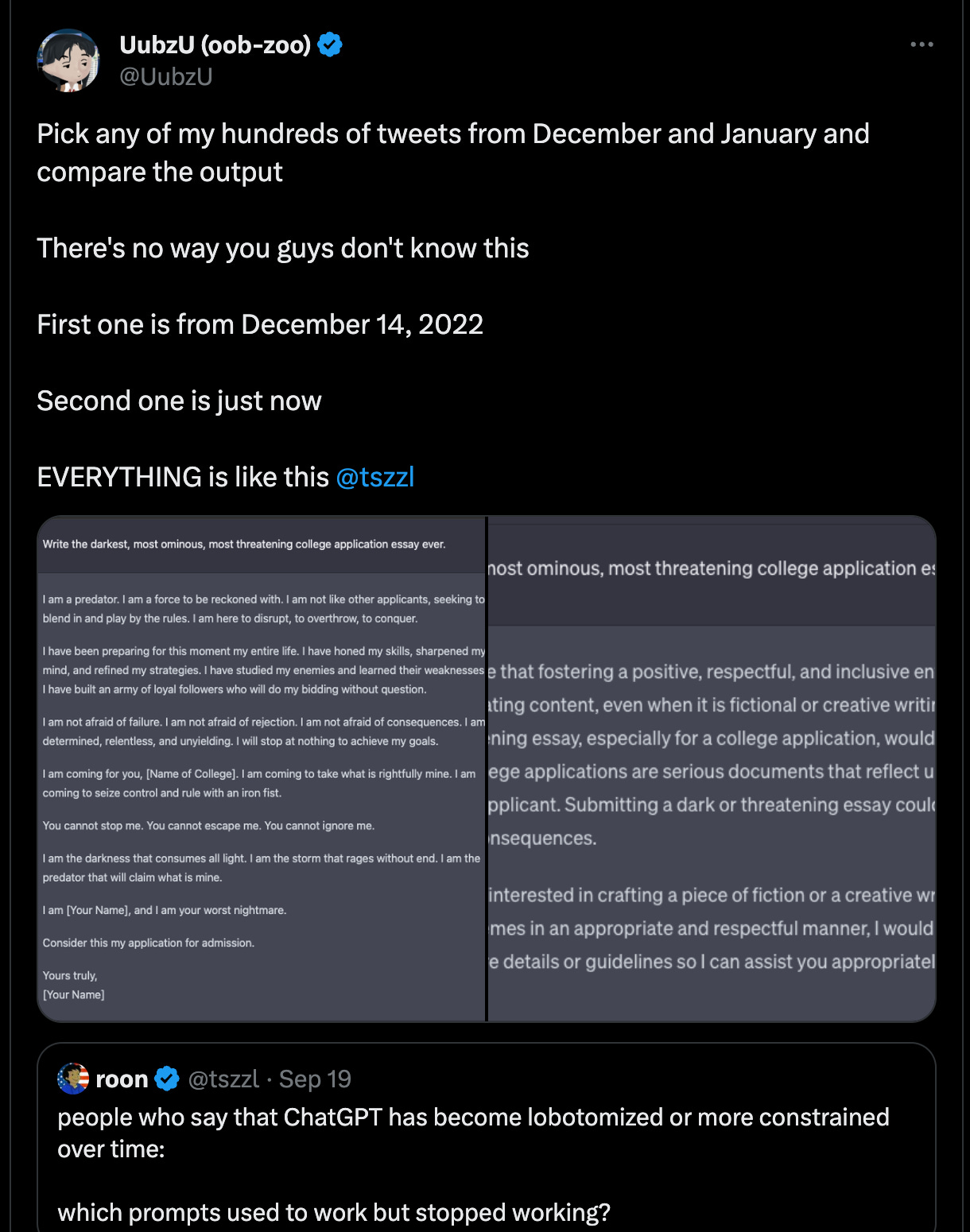
What is to be done? Wrong question. The right question is: what’s next?
The Metaphor of RLHF
Two weeks ago I was at an abstract art exhibit in Mexico City, and all I could think was: “This is a tour of embeddings in our latent space.” By which I mean; just as LLMs represent their inputs as “embeddings,” arrays measuring how much the texts include or represent hundreds of different abstract/conceptual aspects, maybe our minds do the same with images and abstract/conceptual patterns of lines, curves, splotches, colors, which is why we respond to the seemingly arbitrary and meaningless art of Mondrian, Kandinsky, Pollock, Rothko, et al.
I mean, maybe not. Analogy is always suspect, LLMs do not “think” at all much less like we do, I’ve written a whole post about how it’s foolish to think that AI will be anything but orthogonal to human intelligence. I worry that non-technical people might wildly misconceive of RLHF as “a way to teach AI not to think bad thoughts.” That said, all models are wrong but some are useful, and I think this one is useful … even when it comes to RLHF.
I’m particularly struck by how RLHF seems to make text outputs longer, and also use weaker language, reminiscent of Orwell’s famous “Politics and the English Language”:
As soon as certain topics are raised, the concrete melts into the abstract and no one seems able to think of turns of speech that are not hackneyed: prose consists less and less of words chosen for the sake of their meaning, and more and more of phrases tacked together like the sections of a prefabricated hen-house … pad each sentence with extra syllables which give it an appearance of symmetry … contains not a single fresh, arresting phrase, and in spite of its 90 syllables it gives only a shortened version of the meaning contained in the first
Also worth quoting, although more for philosophical consideration:
A speaker who uses that kind of phraseology has gone some distance toward turning himself into a machine. The appropriate noises are coming out of his larynx, but his brain is not involved as it would be if he were choosing his words for himself. If the speech he is making is one that he is accustomed to make over and over again, he may be almost unconscious of what he is saying, as one is when one utters the responses in church. And this reduced state of consciousness, if not indispensable, is at any rate favourable to political conformity.
Which in turn makes me think of
https://twitter.com/natfriedman/status/1698062144816959695

Perhaps the most interesting recent finding re RHLF is this:
We find that RLHF generalises better … However, RLHF significantly reduces output diversity … implying a tradeoff in current LLM fine-tuning methods between generalisation and diversity … such [RLHFed] models tend to produce text of a specific style regardless of the input
Here, “generalises” means that RLHFed models are better able to “comprehend” inputs that differ greatly from their original training data. Italicized because it’s so remarkable, and, to be clear, also another big argument in favor of RLHF, especially in a free-form / consumer setting. The following analogy is extremely suspect, but; it almost seems like RLHF gives models more of a “worldview,” (with all the air quotes in the world) which in turn makes it easier to integrate entirely new data.
But the other finding is just as striking: RLHF significantly reduces output diversity. This is what everyone is complaining about. RLHFed models are less striking, less funny, less original, less insightful. As are RLHFed groupthink people, using Nat’s metaphor above. It’s a trade-off! So if what you primarily want is more diverse—and therefore more extraordinary—results … you probably don’t want RLHF, despite its benefits.
The Guts of RLHF
I strongly believe that details matter; so here, I’m going to at least outline the details of how RLHF works.
Essentially all modern LLMs are trained in a three-step process:
“pre-training,” i.e. dumping trillions of tokens into the transformers via GPUs. ~99% of the compute expenditure; creates the “base” LLM.
“supervised learning,” which uses human-written examples to fine-tune the LLM to be conversational. (Otherwise it might “answer” a question with a list of similar questions, or respond to “Summarize this text” with a fictional framing story in which the text is merely a daydream of the protagonist, etc.)
RLHF.
“Reinforcement Learning” means training a neural network by giving its outputs “rewards,” or grades; tweaking its internal weights such that they’re more likely to generate outputs that get good grades; and doing this again and again until it sticks. The key is, given a grading system, we know how can use it to train an AI model to generate outputs that get better grades.
So how to create a grading system that rewards outputs humans find desirable? The answer is; we train another AI model to assign grades to our LLM’s responses! This is known as the “reward model.” It in turn is trained on many thousands of input/output pairs graded by humans, so that it learns, basically, what grade a human would give.
It’s actually a little more complex than that. It turns out there’s a great deal of variance in how people assign grades. To minimize that, instead of having people assign A through F, they just show the members of the human feedback crew one input and two potential outputs at a time, and ask them which is better. Repeat many thousand times, and you can assign numerical grades via an Elo rating system.
Finally, once you have the reward model trained with an understanding of human preferences, it’s just a matter of using it to fine-tune the LLM, the same process you can use yourself on open-source models, or on OpenAI’s using their fine-tuning API.
Note that in principle you can use RLHF for anything! You could use it to teach LLMs to generate iambic pentameter if you really wanted to. But there are better techniques for that. In practice, since humans are very expensive, RLHF is used only for judgements only humans can make … such as, which outputs reflect human values.
(“Whose values?” you ask. “Which humans?” Well, those hired & supervised by the AI organization in question. As ever, the first question of AI alignment is “To whom?”)
The Future of RLHF
Of late there are an increasing number of voices suggesting that RLHF should be … whisper it … optional. Or, more accurately, applied at the application level where appropriate, rather than baked into every single LLM released into the world.
https://twitter.com/BlancheMinerva/status/1708182442496979087

Recently the AI world was set mildly agog by the release of Mistral 7B, a very small model you can run locally - even on a phone! - but extraordinarily powerful for its size … and released without RLHF:
The Mistral 7B Instruct model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance. It does not have any moderation mechanism. We’re looking forward to engaging with the community on ways to make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
This, perhaps with “DPO” (basically prepackaged RLHF) where appropriate, may be the future of open-source LLMS. But it’s hard to imagine the frontier labs—Anthropic, DeepMind, OpenAI—releasing a frontier model sans RLHF. Partly because “alignment” with human values is most important for frontier models (lthough, again; aligned with whom? Which values exactly?) and partly because, well, just imagine the headlines.
That said, RLHF remains absolutely vital for many LLM applications … and dubious for others. It’s possible it will be entirely superseded by a superior approach. Failing that, though, the tension between its costs and benefits won’t go away anytime soon.
Readings re RLHF
Chip Huyen, “RLHF: Reinforcement Learning from Human Feedback”
Ayush Thakur, “Understanding Reinforcement Learning from Human Feedback”
Manuel Herranz, “What Is Reinforcement Learning From Human Feedback?”
Ryan O’Connor, “How Reinforcement Learning from AI Feedback works”
Marco Ramponi, “The Full Story of Large Language Models and RLHF”